Open access A Bayesian phylogenetic study of the Dravidian language family, by Kolipakam et al. (including Bouckaert and Gray), Royal Society Open Science (2018).
Abstract (emphasis mine):
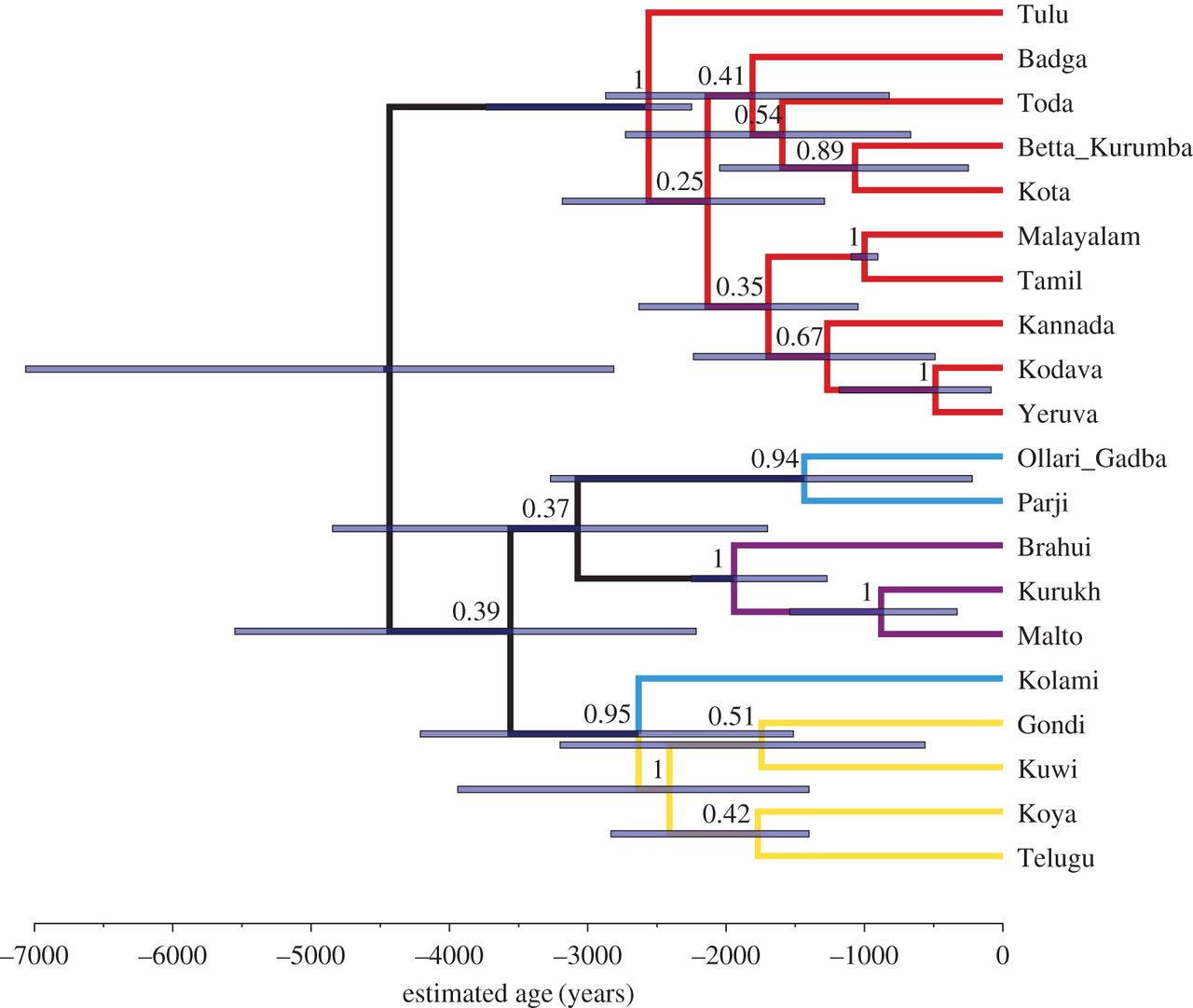
The Dravidian language family consists of about 80 varieties (Hammarström H. 2016 Glottolog 2.7) spoken by 220 million people across southern and central India and surrounding countries (Steever SB. 1998 In The Dravidian languages (ed. SB Steever), pp. 1–39: 1). Neither the geographical origin of the Dravidian language homeland nor its exact dispersal through time are known. The history of these languages is crucial for understanding prehistory in Eurasia, because despite their current restricted range, these languages played a significant role in influencing other language groups including Indo-Aryan (Indo-European) and Munda (Austroasiatic) speakers. Here, we report the results of a Bayesian phylogenetic analysis of cognate-coded lexical data, elicited first hand from native speakers, to investigate the subgrouping of the Dravidian language family, and provide dates for the major points of diversification. Our results indicate that the Dravidian language family is approximately 4500 years old, a finding that corresponds well with earlier linguistic and archaeological studies. The main branches of the Dravidian language family (North, Central, South I, South II) are recovered, although the placement of languages within these main branches diverges from previous classifications. We find considerable uncertainty with regard to the relationships between the main branches.
With every new paper using these revamped pseudoscientific linguistic methods popular in the early 2000s, including glottochronology, Swadesh lists, phylogenetic trees, mutation rates, etc. I feel a little more like Sergeant Murtaugh…
Featured image, from the article: “Map of the Dravidian languages in India, Pakistan, Afghanistan and Nepal adapted from Ethnologue [2]. Each polygon represents a language variety (language or dialect). Colours correspond to subgroups (see text). The three large South I languages, Kannada, Tamil and Malayalam are light red, while the smaller South I languages are bright red. Languages present in the dataset used in this paper are indicated by name, with languages with long (950 + years) literatures in bold.”
See also:
- The origin and expansion of Pama–Nyungan languages across Australia
- Archaeological and anthropological studies on the Harappan cemetery of Rakhigarhi, India
- The Indus Valley Civilisation in genetics – the Harappan Rakhigarhi project
- Mitogenomes show ancient human migrations to and through North-East India not of males exclusively
- The Aryan migration debate, the Out of India models, and the modern “indigenous Indo-Aryan” sectarianism
- New Ukraine Eneolithic sample from late Sredni Stog, near homeland of the Corded Ware culture
- Indo-European and Central Asian admixture in Indian population, dependent on ethnolinguistic and geodemographic divisions
- Asian ancestry of the Roma people in Europe
- Germanic–Balto-Slavic and Satem (‘Indo-Slavonic’) dialect revisionism by amateur geneticists, or why R1a lineages *must* have spoken Proto-Indo-European